Dacon Computer Vision Learning Contest
Predicting numbers obscured by alphabets as MNIST transformed dataset
Team
- Jiwon Yoon
- Kimin Park
- Jaehee Kim
Environment
- Ubuntu 18.04
- Intel i7-10875H
- GeForce RTX 2070 / RAM 8GB
- Jupyter notebook
Skills
- tensorflow 2.3.0
- python
- pandas
- seaborn
Task
Predicting numbers obscured by alphabets as follows:
The rules are we can test the accuracy on the web pages, but we cannot be provided validation dataset until the competition was finished. We cannot use pretrained model or external dataset.

1. Data Preprocessing
We chose three approches:
- Preliminary approach: Removing only letters and did dilation with numbers, but the accuracy was low.
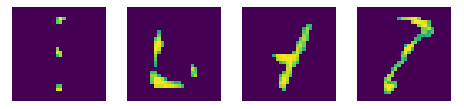
- To extract the feature well, we extracted digits and alphabets individually and then concatenated.
- Using deskew, images were straightened.
- Autoencoder : First we combined each fractions of the numbers individually (1, 1, 1, 1, 1, … → 1) (2, 2, 2, … → 2) When all the number are combined, it looks like below. The reason why we did this is that we were not allowed to use the external data and we tried to teach out model how numbers actually look like because train dataset didn’t have appearances of the number we know as we can see in the above.

With above images, we trained our model how to construct the fractured numbers to whole number and tested it to test dataset.
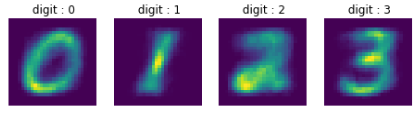
Ideas were good, but unfortunately the accuracy was low.
2. Data Augmentation
- Data augmentation
- ImageDataGenerator: Augmentation was conducted with this function.
- The reason we chose to do augmentation was that the number of dataset was limited. Therefore, we tried to solve this problem with augmentation.(train set 2048 images, test set 20480 images)
3. Modelling
- Model
- DenseNet121
- ReXNet
- XceptionNet
- ReXNet showed highest accuracy. We tried to do stacking Ensemble with k-fold cross validation, but it also showed low accuracy.
- Callback
- EarlyStopping: We used EarlyStopping to prevent overfitting.
- ReduceLROnPlateau: ReduceLROnPlateau was used to decrease learning rate when model is not learning anymore.
- ModelCheckpoint: We compared multiple models with ModelCheckpoint.
Limitation
- We expected the high accuracy when we used Autoencoder because it looks like it became real number in human’s eye. However, it turns out that our model couldn’t extract the features that computer can understand leading low accuracy.
- We should have used CAM to see if the model is learning well.
- We could have applied Semi-Supervised Learning to increase the dataset with limited label because of our small number of datasets.
Results
- Public
- 62/840
- Score : 0.92647
- Private
- 41/840
- Score : 0.90762